

Meta Voicebox: Generative Sprach-KI kann Text-to-Speech und zugleich übersetzen
Voicebox sei die modernste generative Sprach-KI, sagt Meta. So gut, dass die Gefahren bei einer Veröffentlichung zu groß wären und sie unter Verschluss bleibt.
(Bild: Meta)
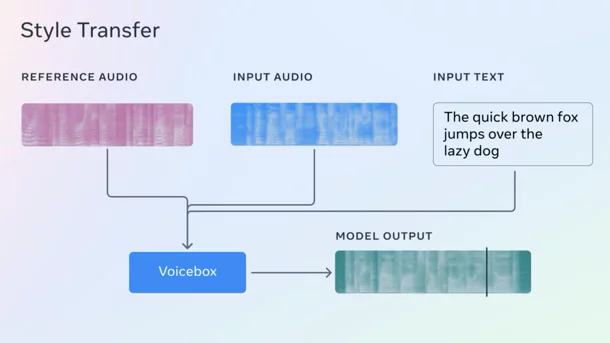
Voicebox ist laut Meta die bisher „vielseitigste generative Sprach-KI“ und ein „Durchbruch“. Weil sie so vielfältig einsetzbar ist und damit auch missbraucht werden kann, veröffentlicht Meta sie allerdings noch nicht. Stattdessen gibt es einen Überblick zur Funktionsweise und Beispiele, was Voicebox alles kann.
Das generative KI-Model kann Audio-Dateien editieren, samplen und verändern. Das Besondere daran ist, dass Voicebox nicht auf nur eine Aufgabe trainiert wurde, sagt Meta, sondern mehrere Aufgaben erfüllen kann. Zudem reichen Voicebox zwei Sekunden lange Aufnahmen, um danach Text in „Audio-Style“ zu verwandeln – was konkret Audio-Style bedeutet, erklären sie nicht. Die Sprache klinge zudem besonders natürlich, also nicht wie eine Computerstimme. Voicebox übertrifft laut Meta das Sprachmodell VALL-E von Microsoft bei Zero-Shot Text-to-Speech in Bezug auf Verständlichkeit (5,9 Prozent vs. 1,9 Prozent Wortfehlerraten) und Audioähnlichkeit (0,580 vs. 0,681), während Voicebox auch noch bis zu 20-mal schneller ist. Vall-E kann laut Microsoft nach drei Sekunden Originaldatei einen Sprecher nachahmen.
Audio-Radiergummi und Echtzeit-Text-to-Audio-Übersetzer
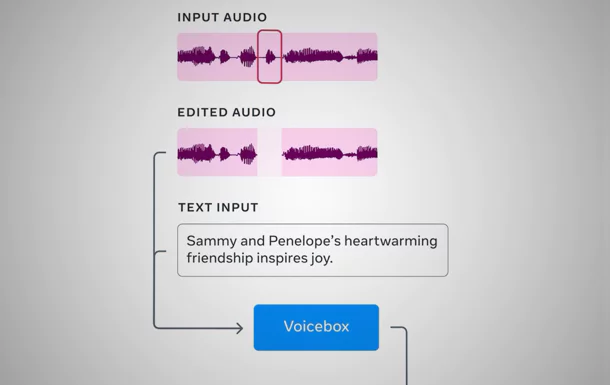
Als Beispiel für das Können gibt es eine Aufnahme, bei der das Bellen eines Hundes aus der Datei entfernt wird, ohne dass der Rest darunter leidet, denn die Passage wird künstlich neu geschaffen, ohne dass der Hund zu hören ist.
Noise Cancelling funktioniert allerdings freilich auch bei anderen Diensten, sogar live, Microsoft nennt unter anderem genau jenes Beispiel eines bellenden Hundes, der bei einer Teams-Besprechung ausgeblendet werden kann. Aber auch Versprecher soll Voicebox herausfiltern und ersetzen können. Meta nennt es einen Audio-Radiergummi.
Voicebox spricht sechs Sprachen, darunter Deutsch, und kann übersetzen – von Text zu Audio in einer anderen Sprache. Grundsätzlich können andere Sprachmodelle übersetzen, der gleichzeitige Weg von Audio zu Text zu Audio ist aber spannend. Meta stellt sich vor, dass man mit dieser Funktion künftig auf natürliche Art und Weise mit jemandem kommunizieren kann, wenn man nicht die gleiche Sprache spricht.
KI-Übersetzer gibt es grundsätzlich viele. Selbst Bing, also die Microsoft-Suche in der GPT-4 steckt, übersetzt beispielsweise Anfragen, die auf Deutsch gestellt werden, ins Englische und gibt daraufhin eine Antwort aus, die vermutlich wieder zurückübersetzt wurde. Das lässt sich an Schlagworten erkennen, die man während der Suchabfrage sieht und testen, wenn man Bing bittet, zu reimen.
„Es gibt viele spannende Einsatzfälle für generative Sprachmodelle, aber aufgrund der potenziellen Risiken des Missbrauchs stellen wir das Voicebox-Modell oder den Code derzeit nicht öffentlich zugänglich“, heißt es im Blogbeitrag von Meta. Man müsse die Balance zwischen Offenheit und Verantwortung finden. „In unserem Papier beschreiben wir detailliert, wie wir einen hochwirksamen Classifier gebaut haben, der zwischen authentischer Sprache und Audio unterscheiden kann, die mit Voicebox erzeugt wurde, um mögliche Risiken zu mindern.“
Meta erklärt, Voicebox basiert auf einem Flow-Matching-Model, einem nicht-autoregressivem generativen Model, das non-deterministic Mapping zwischen Text und Sprache kann. Gemeint ist, dass die Trainingsdaten nicht umfänglich gelabelt sein müssen, sondern eine größere Menge verschiedener Daten mit weniger Aufwand zum Training herangezogen werden kann. 50.000 Stunden gesprochener Sprache und Transkripte zu Audiobüchern von öffentlichen Domains sind in Voicebox geflossen.